
#222 DeepSeek lo cambia todo (¿o no?), pero… ¿qué sabemos realmente de IA?

Hola, soy Samuel Gil.
Esto es Suma Positiva, una publicación sobre tecnología, negocios y humanos leída por más de 28.000 personas cada semana.
No puedo evitar escribir sobre DeepSeek, o mejor dicho, sobre la reacción del mundo tecnológico y financiero al lanzamiento de R1, su último modelo de inteligencia artificial (IA) avanzada.
DeepSeek es especial —o al menos así se ha percibido, que nos guste o no, es lo que muchas veces más importa— por varios motivos, en los que luego entraremos.
Sin embargo, me gustaría que el artículo de esta semana no se centrara sólo en el debate en torno a DeepSeek, sobre el que ya se han escrito demasiados artículos y publicaciones en redes sociales, sino en repasar con vosotros algunos conceptos básicos sobre IA. De este modo, podremos entender mejor toda la información que se ha generado y que generará sobre este tema que, no sé por qué, sospecho que no será poca 😅.
Esta edición de Suma Positiva ha sido patrocinada por:

El mercado inmobiliario está en constante evolución, y sé lo difícil que puede ser identificar buenas oportunidades que permitan maximizar la rentabilidad de tus inversiones. Gestionar todo el proceso de una inversión inmobiliaria puede resultar tedioso y consumir mucho tiempo. Aquí es donde entra PropHero: transforman el proceso de inversión inmobiliaria con un enfoque totalmente data-driven, para que invertir sea simple, rentable y personalizado. Con su análisis avanzado de datos, un modelo predictivo de zonas y el respaldo de su equipo de expertos, te ayudan a identificar las mejores oportunidades de inversión. Además, se encargan de todo el proceso: desde la búsqueda del inmueble ideal hasta la compra, reforma, mobiliario y gestión de alquiler.
¿Te gustaría descubrir las mejores oportunidades de inversión diseñadas para ti? Regístrate en su próxima sesión gratuita de inversión y descubre oportunidades que generarán entre un 6% y un 15% de rentabilidad NETA anual. Deja de complicarte con los detalles, delega en PropHero y comienza a construir tu patrimonio inmobiliario de manera sencilla. ¡Contáctales y da el primer paso para crear tu patrimonio inmobiliario!
¿Quieres patrocinar una edición de Suma Positiva? Toda la info aquí.

DeepSeek lo cambia todo (¿o no?), pero… ¿qué sabemos realmente de IA?
El pasado lunes 27 de enero, el anuncio del modelo de inteligencia artificial chino DeepSeek-R1 provocó una fuerte caída en los mercados bursátiles, especialmente en el sector tecnológico.
Wall Street retrocedió más del 3%, mientras que el NASDAQ sufrió una bajada del 4%. NVIDIA registró pérdidas del 12%, mientras que otras empresas tecnológicas clave como ARM, Amazon, Microsoft y Meta cayeron más del 4%.
📌 NVIDIA, líder mundial en fabricación de chips para inteligencia artificial y la compañía con mayor capitalización bursátil del mundo, vivió una jornada histórica el pasado día 27. Su valor cayó en momentos hasta un 17%, lo que representó una pérdida de entre 400.000 y 600.000 millones de dólares, marcando su peor desplome hasta la fecha.
El impacto no se limitó a NVIDIA. Otras gigantes tecnológicas y hasta empresas del sector energético también registraron caídas significativas, reflejando la incertidumbre global que ha despertado este nuevo competidor en el campo de la IA.En total, se estimó que la caída del mercado alcanzó los 1,2 billones (trillions) de dólares. Este impacto se atribuyó al temor de que DeepSeek R1 pudiera desafiar el dominio tecnológico estadounidense en inteligencia artificial.
¿Cómo es posible que el lanzamiento de un nuevo modelo de IA provocase tal terremoto?
DeepSeek es una startup tecnológica china fundada por el ingeniero y empresario Liang Wenfeng, quien, para más inri, es también es propietario de un fondo de inversión (un hedge fund) llamado High-Flyer.
⚠️ Atención a la aparición en la misma frase de las palabras clave China y hedge fund, dos de los villanos habituales en el imaginario popular.
Más sobre esto luego. R1, al igual que el resto de los modelos de DeepSeek, es de código abierto, lo que significa que su código fuente está disponible para que cualquiera pueda verlo, modificarlo, usarlo y distribuirlo libremente. Esto contrasta con la estrategia de los principales laboratorios de IA estadounidenses como OpenAI o Anthropic, cuyos modelos son cerrados.
🏆 Mención de honor aquí para Meta, que se desmarca de sus competidores con sus modelos LLaMA de código abierto. Google, por su parte, ha reconocido internamente que cree que los modelos de código abierto son el futuro. No obstante, aunque ha realizado contribuciones valiosas al mundo open source, su modelo insignia, Gemini, sigue siendo de código cerrado.DeepSeek-R1 no sólo es abierto y gratuito, sino que es igual o superior en calidad a los modelos de razonamiento más avanzados (como o1 de OpenAI) a una fracción del coste:
Supuestamente 👀 , el coste de entrenar R1 fue de tan solo 5,6 millones de dólares, frente a los más de cien millones que se estima que costó entrenar GPT-4 de OpenAI, que ni siquiera es su modelo más avanzado.
Pero quizás lo más relevante es que ejecutar R1 es unas 27 veces más barato que hacerlo con los modelos de OpenAI, para una misma carga de trabajo.
🔎 Esto, que a primera vista podría parecer espectacular, está en línea con las mejoras en eficiencia que hemos visto en la industria en los últimos años, con caídas de los costes de inferencia de 10x por año a calidad similar.
¿Cómo lo han conseguido?
Sin entrar en demasiados detalles técnicos, DeepSeek ha innovado en dos áreas clave:
Gracias al empleo de una metodología denominada ‘aprendizaje por refuerzo puro’, necesitaron menos datos de entrenamiento, caros y difíciles de conseguir. Hasta ahora se pensaba que esto era imposible. Y no está exento de polémica…
🕵🏻♂️ OpenAI ha acusado a DeepSeek de haber utilizado indebidamente su tecnología para desarrollar sus modelos. Se sospecha que DeepSeek utilizó una técnica llamada “destilación”, que permite entrenar modelos más pequeños usando los resultados de modelos más avanzados, en lugar de entrenar un modelo desde cero. Esta práctica, violaría los términos de servicio de OpenAI si se realizó sin autorización. Microsoft, que tiene una importante inversión en OpenAI, detectó que a finales de 2024, algunas cuentas de desarrolladores afiliadas a DeepSeek estaban generando un tráfico inusual de datos desde la API de OpenAI. Muchos están aprovechando la ocasión para recordarle con sorna a OpenAI que, irónicamente, ellos también habrían utilizado ilegalmente datos protegidos por copyright para entrenar sus modelos.Por desarrollar un software que hace un uso mucho más eficiente del hardware, tanto en el entrenamiento del modelo como en su ejecución.
💡 Recordemos que estos modelos son extremadamente intensivos en el uso de recursos computacionales muy caros y escasos (léase GPUs, chips especializados en cálculos para IA cuyo principal fabricante es NVIDIA, entre otros) y, por ende, en el consumo de energía, tanto durante el entrenamiento como en la ejecución, proceso que en el argot también se denomina ‘inferencia’ o ‘test’.Hasta ahora, nadie había necesitado prestar la suficiente atención a esto (y en IA ya sabemos que ‘attention is all you need’ 😉).
Ante la irrupción de DeepSeek, el mercado se hacía estas preguntas:
¿Tienen las empresas americanas como OpenAI, Google o Anthropic una ventaja competitiva sostenible basada en altas barreras de entrada, como se creía? ¿O será el desarrollo de nuevos modelos algo mucho más asequible en el futuro?
¿Se necesitarán realmente tantísimos chips de NVIDIA en el futuro como su cotización sugiere?
Las caídas del lunes sugieren que la respuesta de los inversores a estas preguntas era ‘no’, pero, como sabemos, los mercados tienden a sobrereaccionar.
Mi impresión (y por supuesto puedo estar equivocado) es que, con un poco más de calma, se ha formado un nuevo consenso en torno a dos ideas clave:
Será difícil establecer una ventaja competitiva duradera únicamente en el desarrollo de modelos. La capa de aplicación (además de la de hardware) es donde parece que se podrá crear y defender más valor.
La demanda de hardware no va a caer, aunque eso no significa necesariamente que NVIDIA vaya a seguir siendo la única gran beneficiada. Ya sea porque desarrollaremos modelos aún más potentes que requieran mayor capacidad computacional, o porque, aunque no lo necesiten, cualquier modelo siempre se beneficiará de más y mejores recursos. Y, sobre todo, porque si la IA se vuelve más accesible, su demanda se disparará. Casos de usos que antes no eran viables ahora ya lo son. ¿Presupuestos limitados o necesidades de escalabilidad enormes? No problemo. Tendremos IA hasta en la sopa. Los más cursis aludían a la famosa paradoja de Jevons, un fenómeno que se ha repetido una y otra vez a lo largo de la historia de la tecnología y la innovación.
🤓 En economía, la paradoja de Jevons se refiere a la situación en la que el progreso técnico o las políticas del Estado conducen a un aumento en la eficiencia con la que se utiliza un factor de producción, reduciendo la cantidad que se requiere de este. Sin embargo, la caída de los precios del mismo promueve su demanda, por lo que aumenta su uso en lugar de reducirse.
A pesar de que los mercados pueden asumir que el aumento en la eficiencia disminuirá el consumo del factor en cuestión, pueden llegar a obviar la posibilidad del surgimiento de este efecto.4 Concretamente, la paradoja de Jevons implica que la introducción de tecnologías con mayor eficiencia energética pueden, a la postre, aumentar el consumo total de energía y, simultáneamente, a un incremento de las emisiones.
Fuente: Wikipedia¿Qué les ha motivado a hacerlo?
Aquí es donde la cosa se pone verdaderamente divertida.
Por un lado, China no tiene acceso a los últimos chips para IA desarrollados en Estados Unidos. Y como el hambre agudiza el ingenio, DeepSeek se ha visto forzado a encontrar ha encontrado la forma de hacer funcionar su modelo en un hardware más modesto.
😱 Aunque DeepSeek R1 fue inicialmente entrenado en GPUs NVIDIA H800 (a las que supuestamente tuvo acceso antes de su prohibición), ahora está utilizando los chips Ascend de Huawei para la inferencia. Toma tiro por la culata 🤦🏻: las prohibiciones no solo han llevado a los chinos a desarrollar un modelo de software similar (para algunos incluso superior), sino que también han impulsado a su industria del hardware a ponerse las pilas.
🇺🇸 La Guerra de los Chips 🇨🇳
La prohibición de vender GPUs a China es parte de una serie de restricciones impuestas por el gobierno de Estados Unidos para limitar el acceso de China a tecnología avanzada de semiconductores, especialmente aquellos utilizados para aplicaciones de IA.
En 2022, el gobierno de EE.UU. excluyó las GPUs A100 y H100 de NVIDIA de las listas de exportación a China, debido a preocupaciones sobre el posible uso militar chino de hardware informático occidental.
Como respuesta, NVIDIA desarrolló la variante A800, específicamente diseñada para el mercado chino. Esta GPU era esencialmente igual a la A100 original, pero con velocidades reducidas para cumplir con las restricciones comerciales.Sin embargo, en noviembre de 2023, el gobierno de EE.UU. implementó nuevas restricciones que también prohibieron la venta de los modelos A800 y H800 a China. Estas nuevas reglas se basaron en el rendimiento de los chips, afectando no solo a los modelos específicos para centros de datos, sino también incluyendo los modelos de gran consumo. Además, se prohibieron los sistemas que incorporan circuitos NVIDIA DGX y HGX, así como futuros lanzamientos que superen cierto umbral de rendimiento.
En diciembre de 2023, la Secretaria de Comercio de EE.UU., Gina Raimondo, advirtió a NVIDIA que no modificara sus chips para eludir las restricciones. Raimondo declaró: "Si rediseñan un chip que permita acceder a la inteligencia artificial, voy a restringirlo al día siguiente". Esta postura refleja la determinación del gobierno estadounidense de mantener su liderazgo en IA y negar el acceso a tecnología punta a China.
En enero de 2025, el gobierno de Biden implementó un nuevo paquete de prohibiciones que busca bloquear la exportación de semiconductores utilizados en aplicaciones de IA a países como China, Rusia, Irán y Corea del Norte. Estas sanciones tienen como objetivo reforzar el dominio global de EE.UU. en el ámbito de la IA.
La nueva regulación divide el mundo en tres niveles: el primer nivel incluye 18 países aliados que no se ven afectados por las sanciones; el segundo nivel abarca 120 países con algunas restricciones; y el tercer nivel, que incluye a China, enfrenta las prohibiciones más estrictas y no recibirá tecnología avanzada de EE.UU.
Fuente Otras teorías más conspiranoicas apuntan en las siguientes direcciones:
Existen dudas (¿fundadas?) sobre la veracidad de algunos de los datos dados por DeepSeek, en especial los relacionados con el coste de entrenamiento del modelo. ¿Por qué querrían mentir? ¿Estarían ocultando que han tenido acceso a tecnología prohibida? ¿Qué han copiado a OpenAI? ¿Querrían exagerar sobre la eficiencia del proceso para animar a la competencia y debilitar a sus competidores?
¿No resulta, cuanto menos, sospechoso que una empresa con vínculos muy fuertes a un hedge fund (¡¡un hedge fund!!) desarrolle un modelo tan potente y lo libere al mundo en código abierto para que todos nos beneficiemos? ¿No será que DeepSeek es, en realidad, un instrumento de High-Flyer para hundir la cotización de NVIDIA y otras tecnológicas, y forrarse con apuestas en corto?
Y puestos a pensar mal. ¿No será que China tiene interés en desatar el pánico en la bolsa estadounidense justo en la semana en que Trump toma posesión, mientras al mismo tiempo presume de sus capacidades tecnológicas? O alternativamente, ¿no será DeepSeek en realidad una herramienta de espionaje del Partido Comunista Chino, una trampa para captar todo tipo de datos de incautos occidentales?
Fundamentos de IA
Para entender todo lo que hemos mencionado hasta ahora, es importante tener una visión general sobre qué es un modelo de inteligencia artificial, cómo se entrena, cómo funciona y qué recursos requiere.
Voy a intentar explicarlo de forma sencilla e intuitiva, priorizando la claridad sobre la precisión (disimulando de paso mi propia ignorancia 😅).
Introducción
El objetivo de un gran modelo de lenguaje (LLM por sus siglas en inglés) es predecir la palabra que con mayor probabilidad sigue a una cadena de texto previa. Por ejemplo, ante la cadena “El cielo está muy nublado. Creo que va a...” el modelo predice que la siguiente palabra más probable será “llover”.
Este comportamiento estadístico es lo que da lugar a las famosas “alucinaciones”. Cuando el modelo no tiene datos actualizados, en lugar de decir “no lo sé”, genera una respuesta errónea basada en patrones de información que ha visto antes.
🤓 Para ponerlo en contexto, los LLMs (Large Language Models) son un tipo de Transformer, que es una arquitectura de red neuronal diseñada para procesar secuencias de datos.
Las redes neuronales son modelos matemáticos inspirados en el cerebro humano y, cuando tienen muchas capas para aprender patrones complejos, se consideran parte del Deep Learning.
El Deep Learning es una subcategoría del Machine Learning, que engloba técnicas en las que los sistemas aprenden a partir de datos sin ser programados explícitamente.
A su vez, el Machine Learning es un subconjunto de la Inteligencia Artificial, el campo general que abarca cualquier sistema capaz de realizar tareas que normalmente requieren inteligencia humana.El modelo de IA es sólo una parte de un sistema de software más amplio, como ChatGPT, que incluye el resto de componentes esenciales para su funcionamiento, como la interfaz de usuario, entre otros. Todo esto permite que el modelo se ejecute correctamente y que un humano pueda interactuar con él de manera fluida.
Pero no nos desviemos.
En la práctica, un LLM es un conjunto de matrices gigantes llenas de números con muchos decimales. A estos números los llamamos pesos.
📌 En un modelo de IA, los parámetros incluyen tanto los pesos como otras variables configurables. Por lo general, el número de parámetros (que en su inmensa mayoría son pesos por lo que muchas veces ambos términos se usan como sinónimos) se usa como referencia del tamaño del modelo, es decir, de su capacidad para aprender y procesar información.
OpenAI no ha revelado oficialmente el número exacto de parámetros que componen GPT-4. Sin embargo, diversas fuentes estiman que GPT-4 podría tener alrededor de 1,8 billones (trillions) de parámetros, lo que lo haría más de diez veces más grande que su predecesor, GPT-3, que cuenta con 175.000 millones de parámetros.Estas matrices transforman el texto de entrada —que, como veremos, primero se convierte en un vector de números— en el texto de salida, a través de una infinidad de cálculos matemáticos. A este proceso se le llama inferencia.

Tokenización y embeddings
Decíamos al inicio de esta sección que el modelo transforma el texto de entrada en un vector de números, que luego es procesado por la red neuronal (las matrices de pesos) para ofrecerlos la salida.
Vamos a profundizar un pelín más en esta parte del proceso.
El modelo, en lugar de palabras, utiliza tokens, que pueden ser palabras, partes de palabras o signos de puntuación, dependiendo del método de tokenización utilizado.
Con el método de tokenización de subpalabra, la frase
“¡Eso es impresionantemente difícil!”
se tokenizaría en:
[“¡”, “Eso”, “es”, “impresion”, “##ante”, “##mente”, “difícil”, "!"]
De esta forma el modelo no necesita conocer tantas palabras diferentes, sino que puede derivar su significado a partir de partes más pequeñas. Una vez que hemos dividido el texto de entrada en tokens, cada token se convierte en un vector numérico llamado embedding, que representa su significado.
Estos vectores suelen tener miles de dimensiones para capturar de manera precisa las relaciones semánticas y sintácticas entre las palabras. Sin embargo, para simplificar, podemos imaginar un ejemplo en tres dimensiones.
📌 Como es lógico, a mayor número de dimensiones, mayor es la capacidad del modelo para capturar matices y relaciones entre palabras, pero también aumenta la complejidad de los cálculos y, por tanto, el coste computacional.Por ejemplo, los tokens “perro” y “gato” se representarán con vectores cuyas coordenadas los situarán cerca en el espacio vectorial, ya que ambos son animales domésticos. En cambio, la distancia entre estos vectores y los de palabras como “azul” o “escribir” será mucho mayor, ya que pertenecen a categorías semánticas diferentes.
Otro ejemplo para entender mejor cómo estos vectores capturan relaciones semánticas. En el espacio de embeddings, la operación “rey - hombre + mujer” (más precisamente a la suma y resta de sus vectores correspondientes) podría dar un vector cercano al embedding de “reina”.
El proceso para transformar tokens en embeddings es aprendido por el modelo durante la fase de entrenamiento, donde ajusta automáticamente los valores de los vectores para reflejar las relaciones entre las palabras basándose en grandes cantidades de datos.
Contexto y atención
Otro concepto clave en este tipo de modelos es el de ventana de contexto, que es el número máximo de tokens que el modelo puede procesar a la vez.
📌 En el caso de GPT-4, la ventana de contexto estándar es de 8.192 tokens (aproximadamente 6.000-6.500 palabras en español. Esto equivale a un documento de unas 12-15 páginas), aunque hay una versión especial con una ventana de contexto de 32.000 tokens. Procesar una gran cantidad de tokens simultáneamente permite al modelo comprender de manera más precisa las relaciones entre ellos y determinar cuáles son más relevantes. Esto es posible gracias al mecanismo de atención, la característica principal de la arquitectura Transformer.
Durante la generación de texto, el modelo toma una secuencia de entrada (el “prompt”) y construye la respuesta token por token, utilizando un proceso iterativo basado en el contexto.
Para ello, sigue estos pasos:
Predicción del siguiente token: A partir del contexto disponible, el modelo selecciona el token más probable que debe seguir.
Actualización del contexto: El token generado se añade a la secuencia.
Repetición del proceso: Con el contexto actualizado, el modelo vuelve a predecir el siguiente token y repite este ciclo hasta completar la respuesta.
Este mecanismo permite que el modelo genere texto de manera fluida y coherente, ajustándose dinámicamente al contenido ya procesado.
RAG
RAG (Retrieval-Augmented Generation) es una técnica que combina búsqueda de información (retrieval) con generación de texto (generation) en modelos de lenguaje.
Su objetivo es mejorar la precisión, reducir la alucinación y permitir que los modelos trabajen con información más actualizada o específica sin necesidad de re-entrenarlos.
Funciona así:
Antes de generar una respuesta, el modelo busca información relevante en una base de datos, documentos o fuentes externas (como páginas de Internet).
Una vez recuperada la información relevante, se introduce como contexto en el modelo de lenguaje.
El modelo usa este contexto para generar una respuesta más precisa y fundamentada.
📌 Por ejemplo, tanto Perplexity como NotebookLM usan RAG (en el primer caso fuentes de internet como páginas web o vídeos de YouTube y en el segundo documentos subidos por el usuario) para mejorar el contexto del modelo antes de generar una respuesta. ¿Razonamiento?
Una de las cosas más fascinantes es ver cómo modelos avanzados como DeepSeek-R1 o OpenAI-o1 “razonan”, es decir, descomponen un problema en pasos intermedios para llegar a un solución, en una secuencia de “pensamientos” llamada “chain-of-though”.
Todo esto ocurre durante la fase de inferencia o “test-time” y es donde se prevé que se hagan más avances próximamente.
📌 Hasta ahora, la mejora de los modelos de IA ha dependido en gran medida del aumento en la cantidad de datos de entrenamiento y de la capacidad computacional, a lo que se conoce como "ley de escalado". Sin embargo, también han sido clave innovaciones en arquitectura, optimización y técnicas de entrenamiento, que han permitido avances más allá del simple aumento de recursos.Aquí un ejemplo tontorrón de chain-of-thought:
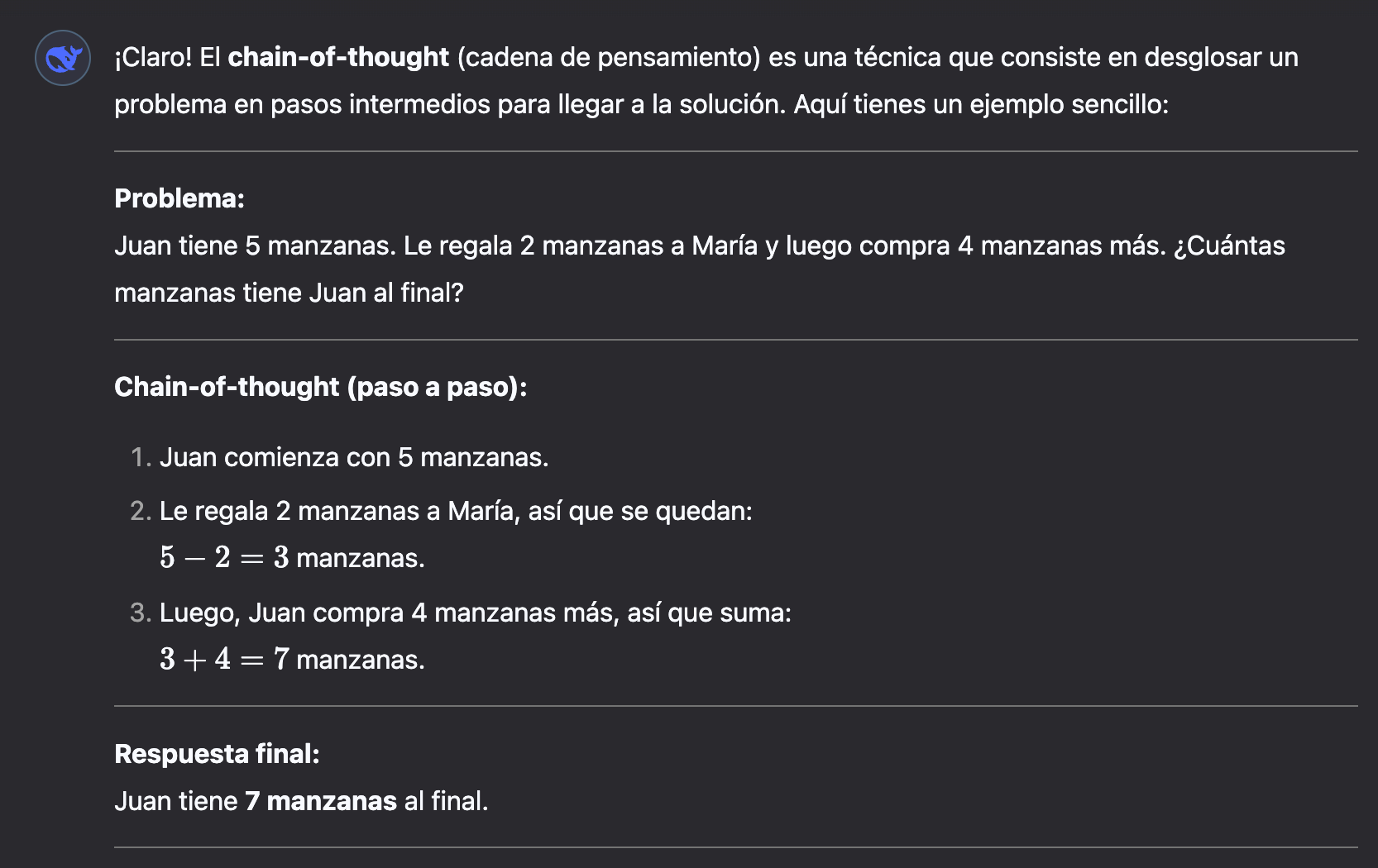
Aunque el modelo está técnicamente prediciendo tokens, su capacidad para “razonar” surge de:
Contexto amplio: Los modelos modernos tienen una ventana de contexto lo suficientemente grande como para mantener coherencia y seguir cadenas de pensamiento complejas.
Patrones aprendidos: Durante el entrenamiento, el modelo ha visto millones o billones de ejemplos de texto que incluyen razonamientos, explicaciones, y soluciones a problemas. El modelo aprende a imitar estos patrones.
Emergencia de habilidades: A medida que los modelos crecen en tamaño y se entrenan con más datos, emergen habilidades como la resolución de problemas, la inferencia lógica y la comprensión de conceptos abstractos, aunque estas habilidades estén basadas en la predicción de tokens.
¿Realmente razonan?
Aunque los modelos pueden parecer que razonan, no tienen una comprensión real del mundo como los humanos. Simplemente están generando secuencias de texto que estadísticamente tienen sentido dado el contexto.
Además hay un gran dependencia del entrenamiento. Si un modelo no ha sido expuesto a suficientes ejemplos de un tipo específico de razonamiento, es probable que no pueda generalizar bien en ese ámbito.
Entrenamiento
Como decíamos, el proceso de entrenamiento se encarga de ajustar los valores de los pesos. Lo hace ‘aprendiendo’ a partir de un conjunto de datos de entrenamiento, que en nuestro ejemplo es texto.
Durante la fase pre-entrenamiento, de manera secuencial, el modelo procesa fragmentos de texto y ajusta reiterativa y astutamente los pesos (que inicialmente tienen valores aleatorios) hasta que la entrada (la parte inicial del fragmento) genere la salida deseada (la última palabra de la cadena). El proceso se repite millones o billones de veces con diferentes ejemplos de texto hasta que el modelo alcanza un nivel de precisión óptimo.
Cuando el conjunto de datos de entrenamiento es muy grande (por ejemplo, y sin exagerar, prácticamente todo el texto disponible en internet), este proceso puede durar meses y requiere una enorme capacidad de cómputo (y por ende de energía). En particular, se necesita hardware especializado en cálculo paralelo —fundamental para las operaciones matriciales— como las GPUs.
📌 Como ya hemos visto, entrenar el modelo implica ejecutarlo billones de veces, lo que equivale a que miles de personas del mundo lo ejecutaran miles de veces. A lo que voy es que la inferencia a gran escala también es costosa en términos de computación, pues en esencia estamos haciendo lo mismo y se necesita la misma infraestructura. Una vez que el modelo ha sido pre-entrenado, suele pasar por dos fases adicionales: post-entrenamiento y fine-tuning (opcional).
El post-entrenamiento es una fase de refinamiento que se aplica después del entrenamiento base y antes de poner el modelo en producción. El objetivo es hacer que el modelo sea más útil, seguro y alineado con objetivos específicos. Se trata de evitar respuestas dañinas o incorrectas.
En el caso de ChatGPT, se utilizó RLHF (Reinforcement Learning from Human Feedback), un método en el que humanos evaluaron las respuestas del modelo y este fue ajustado en base a esas evaluaciones.
📌 Además de los sesgos ya presentes en los propios datos de entrenamiento, en esta fase entran en juego, de manera significativa, los sesgos culturales y políticos del creador del modelo.El fine-tuning es una técnica que consiste en tomar un modelo ya entrenado y entrenarlo nuevamente con un conjunto de datos más específico, con el objetivo de especializar el modelo en una tarea concreta sin necesidad de entrenarlo desde cero.
Por ejemplo, OpenAI entrenó GPT-4 con un gran conjunto de datos generales (internet, libros, artículos, etc.), pero si una empresa quiere un chatbot especializado en medicina, puede hacer fine-tuning con datos médicos específicos para mejorar su precisión en ese ámbito.
📌 Fine-tuning es ideal cuando quieres que el modelo aprenda de forma permanente conocimientos especializados o mejore su razonamiento. RAG, en cambio, es más eficiente cuando necesitas que el modelo acceda a información actualizada sin reentrenamiento. En muchos casos, la mejor solución es combinarlos: usar RAG para recuperar información en tiempo real y fine-tuning para mejorar la especialización del modelo.Infraestructura
Al igual que cualquier otro software, un modelo de IApuede estar alojado en infraestructura propia o de terceros, siempre y cuando esta cumpla con los requisitos técnicos necesarios. En el caso de los modelos de IA, especialmente aquellos que requieren un alto poder de procesamiento, es fundamental contar con una infraestructura robusta, que suele incluir un conjunto significativo de GPUs para manejar las operaciones intensivas en cálculo.
Uso de modelos cerrados como GPT-4
Para utilizar un modelo cerrado como GPT-4, existen varias opciones:
Versión web de ChatGPT: Puedes acceder directamente a través de tu navegador visitando https://chatgpt.com/. Esta versión está alojada en los servidores de OpenAI, los cuales pueden estar distribuidos en diversas regiones gracias a proveedores de infraestructura en la nube como Microsoft Azure. Alternativamente, también puedes utilizar las aplicaciones móviles o de escritorio disponibles.
Desarrollo de software con API: Si en lugar de usar la interfaz de usuario prefieres desarrollar una aplicación que aproveche las capacidades de un modelo como GPT-4, puedes hacerlo desde cualquier entorno (local o en la nube). Sin embargo, el modelo en sí seguirá alojado en la infraestructura de OpenAI, a la cual accederás mediante una API. En este caso, no es posible desplegar el modelo en tu propia infraestructura, ya que los modelos cerrados como GPT-4 no están disponibles para su instalación local.
Uso de modelos abiertos como DeepSeek o LLaMA
Con modelos de código abierto como DeepSeek o LLaMA, tienes más flexibilidad. Además de las opciones mencionadas anteriormente (uso a través de interfaces web o APIs), puedes desplegar estos modelos en tu propia infraestructura. Esto incluye:
Data center propio: Si cuentas con el hardware necesario, como GPUs adecuadas, puedes instalar y ejecutar el modelo en tus propios servidores.
Infraestructura en la nube: También puedes desplegar el modelo en servidores en la nube, lo que te permite escalar según tus necesidades sin preocuparte por el mantenimiento del hardware.
En resumen, mientras que los modelos cerrados como GPT-4 están restringidos a la infraestructura del proveedor, los modelos abiertos ofrecen la ventaja de poder ser desplegados en entornos propios, brindando mayor control y flexibilidad.
Gracias por leer Suma Positiva.
Si te ha gustado esta edición, no te olvides de dar al ❤️ y de compartirla por email o redes sociales con otras personas a las que les pueda gustar.
Suscríbete para no perderte ninguna futura edición.
Me quito el sombrero ante tu artículo, querido Samuel.
Me parece que has hecho una excelente narrativa de los hechos ocurridos y porqué han pasado, de forma que cualquier persona principiante en este tema que supo de Deepseek ayer por la tarde en un post chapucero de LinkedIn, como yo, pueda con tu ayuda comprender de una mejor manera los hechos y por qué es un tema que ha recibido tanta atención y horas de escritura.
No paso por alto el repaso de conceptos básicos de IA que has hecho, el cual me ha permitido darme cuenta de todo lo que no sé y mejora la base de conocimientos que ya tenía los minutos previos al leer tu artículo.
Justo una hora antes de leer tu artículo, me había expuesto a otro artículo sobre Deepseek, pero este tampoco se centraba en explicar los detalles de la optimización de chips, o investigar sobre si DeepSeek no ha partido desde cero o ha utilizado como entrada la salida de OpenAI para aportar una tenue luz al debate. Nada de eso. Ese artículo se centraba en identificar y desarrollar los principios fundamentales y patrones que cumple el caso de DeepSeek para que los podamos transferir luego a cualquier ámbito de nuestras vidas.
Te lo nombro Samuel porque, mientras tú mencionas los motivos del logro de dicha startup china, como el impedimento del chip ban a China como cuna de la innovación o el descubrimiento de un camino que parecía imposible, el autor de este otro artículo se dedica a desarrollar los hechos que identificas explicando de manera sublime cómo la restricción que parecía condenarlos a ir por detrás se convirtió en la chispa de su ventaja competitiva o cómo pudieron recorrer un camino que era imposible.
Ambos usáis la noticia de Deepseek, no para escribir un nuevo bloque de texto más sobre los detalles, lo técnico, etc. Sino para aportar un enfoque completamente distinto, fresco y enriquecedor. Desde la narrativa de los hechos, tú la complementas con una excelente base de IA, y esta otra persona, con la identificación y desarrollo de los patrones y principios fundamentales, logra que de igual el momento en el que leamos los elementos que expone porque son útiles de manera indefinida o, al menos, durante mucho tiempo.
Me han gustado tanto ambos artículos, y sobretodo, me ha parecido tan fascinante como vuestros artículos se complementan tan bien, que como lector de ambos me hubiese gustado que ambos artículos se pudieran fusionar en uno sólo como he visto que hacen otros escritores cuando colaboran entre ellos. Pero esto sé que es fácil pedirlo desde el lado del consumidor.
Muchas gracias Samuel por dedicarle un artículo a esta noticia y usarla para explicar conceptos los conceptos básicos de IA, que personalmente creo que la mayoría no dominamos tanto como tú, aunque a lo mejor estoy proyectando mi bajo conocimiento sobre este tema en el resto de personas. Al menos tu explicación sobre la tokenización me ha ayudado a despejar dudas que aún mantenía en mi cabeza.
Sobre el artículo que te menciono, te dejo el enlace a él en el final de este mensaje para que puedas poner a prueba lo que digo y verificar que ves el mismo talento y valor que yo detecto en sus líneas. Si llegas a echarle un ojo me gustaría conocer, como lector tuyo, tu opinión sobre ese artículo que aprovecha el caso de Deepseek para aportar algo nuevo, único y valioso para todos. Que sepas que ya he hecho un comentario similar a esta persona sobre tu artículo, a ver si así puedo daros mi agradecimiento en forma de intento de conexión, creo que virtuosa, más que en meras palabras.
Y perdona por el textaco.
Un abrazo.
https://josefortes.substack.com/p/56-deepseek-presion-darwiniana-restricciones-lo-imposible-y-la-innovacion
Felicidades por el artículo. Normalmente no es habitual encontrar explicaciones de cómo funciona la IA con la claridad y con los matices importantes que aquí he visto. Las explicaciones en muchos sitios la siguen dejando como una caja negra y abstracta. El resto del artículo también muy aclaratorio, poniendo sobre la mesa muchos elementos para que cada uno haga su propio chain-of-thought :)
Si me permites un complemento, esta arquitectura de transformer permite procesar los token de un prompt en paralelo (los modelos iniciales eran secuenciales), por eso las GPU de NVIDIA subieron tanto de valor, es como una CPU pero con una arquitectura que permite realizar muchas operaciones en paralelo, hasta ahora el caso clásico era el procesamiento gráfico.